
2025-04-30 10:18
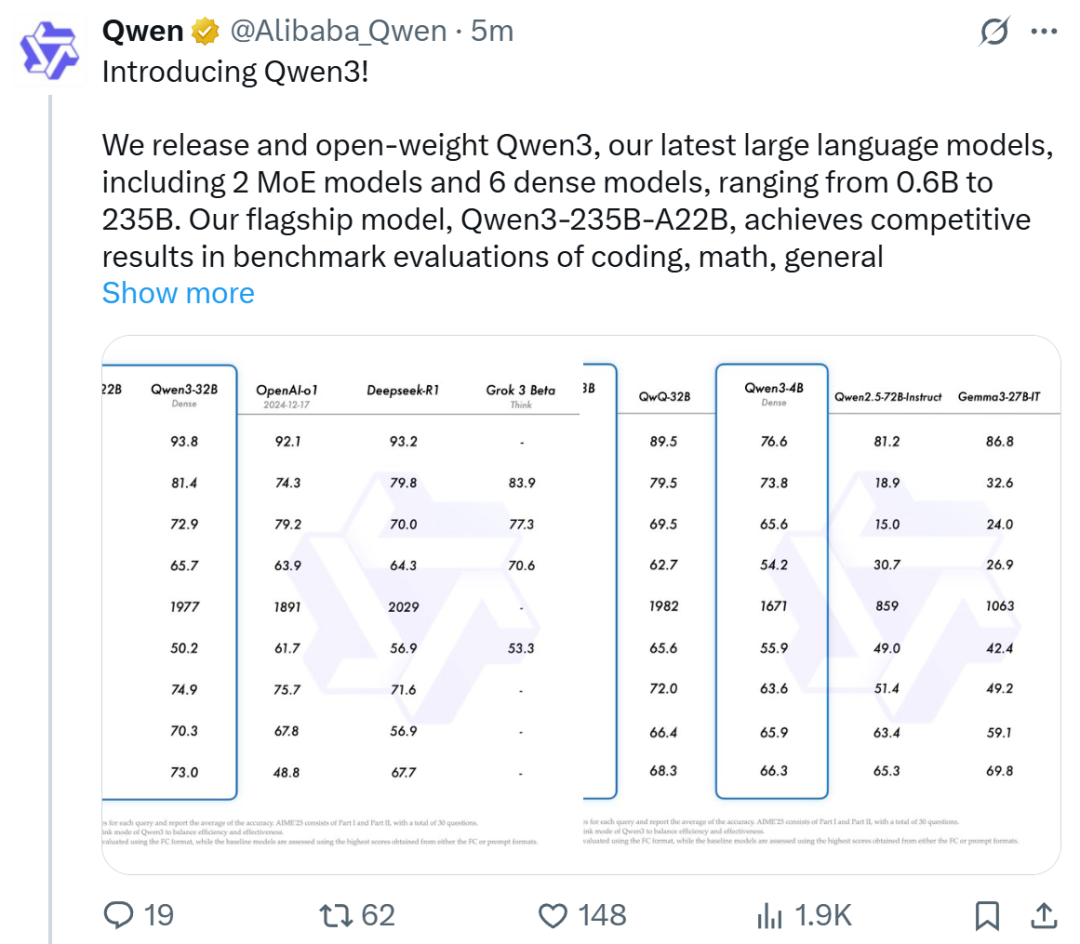 今天清晨,昨晚加热的Qwen3系列模型,引起了AI Global Circle的广泛关注,最终正式发布! QWEN3模型仍使用松散的Apache2.0协议来采购。全球开发人员,研究和商业机构可以免费下载和商业化在Huggingface,Modai社区和其他平台上的模型,或通过阿里巴巴云Baiilian致电QWEN3 API服务。 huggingface地址:https://huggingface.co/collections/qwen/qwen3-67dd247413f0e2e2e4f653967fmodelscope地址: https://github.com/qwenlm/qwen3博客地址:https://qwenlm.github.io/blog/blog/qwen3/trial地址:https://chat.qwen.ai/具体而言,具体地说版本):MOE型号:QWEN3-235B-A22B和QWEN3-30B-A3B;其中235b和30b是参数的总体积,分别为22b和3b激活体积的量。密集型模型:QWEN3-32B,QWEN3-14B,QWEN3-8B,QWEN3-4B,QWEN3-1.7B和QWEN3-0.6B。下表显示了这些模型的详细参数:拥抱面已经启动了22个QWEN3系列的不同模型。目前,QWEN3系列中的三个较大型号也在QWEN CHAT Web版本和移动应用程序中启动。在性能方面,在诸如代码,数学和一般能力之类的基准测试中,QWEN3-235B-A22B旗舰模型播放与领先的模型相当,例如DeepSeek-R1,O1,O3-Mini,Grok-3和Gemini-2.5-Pro。此外,小型MOE QWEN3-30B-A3B模型参数的数量为QWQ-32B的10%,但性能较好。即使是QWEN3-4B之类的小型型号也可以匹配QWEN2.5-72B的教学性能。尽管性能大大提高,但扩大QWEN3的成本也大大下降。只能部署4个H20全血版本和视频记忆消耗只是具有相似性能的模型的三分之一。该博客的博客还提供了一些建议的设置:“对于部署,我们建议诸如Sglang和Vllm之类的框架;供本地使用,例如Ollama,LMSStudio,MLX,Llama.cpp和Ktransformers等工具,强烈推荐我们的Inner offormestions in Innervositions in Innervose。促进了范围的范围。这是跨越的范围。这些剪裁的模型。。 QWEN3版本还引起了全球AI和开放资源社区的关注,我们看到的也是一个充满赞誉的屏幕。它的表现如何?机器的心脏也做了一些简单的尝试。首先,有一个简单的推理测试问题,QWEN3-235B-A22B可以意外地处理它。 2倍快速动画接下来,我们尝试了一个更复杂的编程任务:用像素样式编写蛇游戏。同时还有另一个要求。在游戏中,有一个坦率的家伙追逐我们控制的蛇。咬伤时,蛇的长度一半将消失。当蛇撞到墙壁或咬伤时,游戏结束或长度不到2。该视频没有加速。 QWEN3-235B-A22B已在大约3个Minuto中使用了这项任务。经过简单的测试,我意识到它通常很有趣,但是有一些虫子,例如平顶家伙的速度非常快。但是考虑到这是QWEN3-235B-A2提供的镜头结果2b在简单的癫痫发作下,完全可以接受。我认为,更复杂的及时工程和次数优化可以取得更好的结果。我们还测试了Olllama的QWEN3系列QWEN 0.6B中最小的模型。看来,这种可以在普通手机上正确运行的小型模型不仅很快,而且足以完成许多阳光理性的活动。训练后的模型,例如QWEN3-30B-A3B及其预熟化的基座模型(例如基于QWEN3-30B-A3B)的模型现在可以在平面上购买,例如拥抱面,ModelsCope和Kaggle。对于部署,我们建议SGLANG和VLLM等框架;对于本地用途,强烈建议使用Olllama,Lmstudio,MLX,Llama.cpp和Ktransformers等工具。这些选项可确保用户可以轻松地将QWEN3在其工作流程中包括在内,无论是用于研究,开发还是劳动环境。目前,三个主要的亮点,QWEN3模型在许多方面都得到了增强。首先,两个支持思维方式,以下是:思维方式,模型逐渐推理,并在仔细考虑之后给出了最终答案,这适用于需要深思熟虑的复杂问题。模式不思考,模型为SimplyLeng问题提供了快速,近端的响应,该响应需要高于深度的速度。这种灵活性使用户可以根据特定的控制控制模型进行“思考”。例如,可以通过扩展理解措施来解决复杂的问题,而简单的问题可以直接快速地回答。至关重要的是,这两种模式的结合极大地提高了该模型实现稳定,有效控制“预算思维”的能力。 QWEN3提出的测量和平稳的性能改进与分配的计算信息推理预算直接相关。可以预测,这样的设计使用户更容易为多种玩家配置特定的预算。这下图显示了基准测试集中的无思想模式和心态的预算预算变化的趋势,例如AIME24,AIME25,LiveCodeBech(V5)和GPQA Diamond。其次,支持更多语言。当前,QWEN3模型支持119种语言和方言。改进的多语言功能为国际应用程序开辟了新的可能性,使更多的全球用户能够体验模型的强大技能。这些语言专门包括在以下内容中:第三,代理商的能力得到了增强。如今,该代理已成为大型模型领域的主要功能之一,尤其是最近引入了MCP模型上下文协议伟大的应用程序。目前,QWEN3模型和代码代码的功能得到了增强,包括加强对MCP的支持。我们可以查看以下示例(获取Qwenlm的库Markdown Content,然后绘制一个显示数字的条形图恒星的恒星),显示Qwen3如何与环境进行思考和相互作用:预训练数据达到36万亿代币和火车以获得混合的理解。就预训练而言,将QWEN3数据集与QWEN2.5进行了比较。 QWEN2.5在18万亿代币中进行了预训练,而Qwen3使用的数据量几乎是两倍,达到了近36万亿代币,涵盖了119种语言和方言。为了生成大型数据集,开发团队不仅从网络中收集数据,还从PDF文档中获取信息。他们使用QWEN2.5-VL从这些文档中获取文本,并提高了QWEN2.5所获得的内容的质量。此外,为了增加数学和代码数据的数量,开发团队在数学和代码字段中使用了两个专业模型,即QWEN2.5-MATH和QWEN2.5-编码,以合成数据,并合成不同的数据表格,包括教科书,问题和sidelines和Snippets。具体Y,预训练过程分为以下三个阶段:在第一阶段(S1),该模型先前接受了超过30万亿代币的训练,具有4K令牌上下文长度。这个阶段提供了基本语言技能和常识的模型。在第二阶段(S2)中,通过增加数据NA的比例(例如STEM,编程和推理活动)来改善数据集,然后在另外5万亿个代币中对模型进行培训。在最后阶段,使用高质量上下文数据将上下文的长度扩展到32K代币,以确保模型可以有效地处理更长的输入。由于改进了模型的体系结构,增加了培训数据和更有效的培训技术,因此QWEN3密度基本模型的整体性能与具有更多参数的QWEN2.5基本模型相当。例如,qwen3-1.7b/4b/8b/14b/32b基础与qwen2.5-3b/7b/7b/14b/32b/72b基础相当y。尤其是在STEM,编码和推理字段中,QWEN3密集的主模型的性能比较大的QWEN2.5模型更好。可以看出,QWEN3 MOE基本模型在QWEN2.5密集的基本模型中具有相似的性能,具有10%的激活参数,从而大量节省了培训和识别成本。同时,QWEN3在训练后阶段也进行了优化。为了提出一个混合模型,可以同时具有思考和推理并迅速做出反应的混合模型,开发团队已经实施了四个阶段的训练过程,包括:(1)长时间思考的连锁冷启动,(2)长时间思考的链条加强学习,(3)思维模式融合和(4)总体兴奋剂研究。在第一阶段,模型使用多种长期数据适当使用,涵盖了各种活动和领域,例如数学,代码,逻辑推理和STEM问题。此过程旨在为模型配备Pangi的基本功能Duction。二阶该段落的重点是在大规模加强研究中,使用基于规则的奖励来增强模型探索和研究技能。在第三阶段,该模型非常关注组合数据,包括长链思维数据和常用的教学数据正确调整,并结合了在思维模型中不思考的模式,确保推理和快速响应的不间断组合。在第四阶段,加强研究应用于20多个公共领域的活动,包括遵守教学,遵守格式以及代理商进一步增强模型的整体技能和适当不利行为的能力。 Qwen已成为世界开放资源的第一大型号。 Qwen3的发布是阿里巴巴·汤蒂·Qianwen的另一个里程碑。比较Llama 4系列模型收到的社区反馈,QWEN系列无疑成为了开放世界的数量NT也受到数据的支持。据了解,阿里巴巴·蒂吉(Alibaba Tgyyi)开设了200多个型号,在全球范围内下载了超过3亿个型号,源自QWEN的100,000多个型号,该模型超过了Llama,并成为世界上最大的开源组。随着时间的推移,QWEN,LLAMA和MISTRAL系列开放资源模型的衍生模型数量增加。在AI的全球技术激烈竞争的后面,阿里巴巴Thyi Qianwen通过持续的现代技术和开放合作促进了AI技术的知名度和发展,展示了TS技术公司在全球开放资源AI生态系统中的强大影响。参考链接:https://x.com/alibaba_qwen/status/19169620876766612998
今天清晨,昨晚加热的Qwen3系列模型,引起了AI Global Circle的广泛关注,最终正式发布! QWEN3模型仍使用松散的Apache2.0协议来采购。全球开发人员,研究和商业机构可以免费下载和商业化在Huggingface,Modai社区和其他平台上的模型,或通过阿里巴巴云Baiilian致电QWEN3 API服务。 huggingface地址:https://huggingface.co/collections/qwen/qwen3-67dd247413f0e2e2e4f653967fmodelscope地址: https://github.com/qwenlm/qwen3博客地址:https://qwenlm.github.io/blog/blog/qwen3/trial地址:https://chat.qwen.ai/具体而言,具体地说版本):MOE型号:QWEN3-235B-A22B和QWEN3-30B-A3B;其中235b和30b是参数的总体积,分别为22b和3b激活体积的量。密集型模型:QWEN3-32B,QWEN3-14B,QWEN3-8B,QWEN3-4B,QWEN3-1.7B和QWEN3-0.6B。下表显示了这些模型的详细参数:拥抱面已经启动了22个QWEN3系列的不同模型。目前,QWEN3系列中的三个较大型号也在QWEN CHAT Web版本和移动应用程序中启动。在性能方面,在诸如代码,数学和一般能力之类的基准测试中,QWEN3-235B-A22B旗舰模型播放与领先的模型相当,例如DeepSeek-R1,O1,O3-Mini,Grok-3和Gemini-2.5-Pro。此外,小型MOE QWEN3-30B-A3B模型参数的数量为QWQ-32B的10%,但性能较好。即使是QWEN3-4B之类的小型型号也可以匹配QWEN2.5-72B的教学性能。尽管性能大大提高,但扩大QWEN3的成本也大大下降。只能部署4个H20全血版本和视频记忆消耗只是具有相似性能的模型的三分之一。该博客的博客还提供了一些建议的设置:“对于部署,我们建议诸如Sglang和Vllm之类的框架;供本地使用,例如Ollama,LMSStudio,MLX,Llama.cpp和Ktransformers等工具,强烈推荐我们的Inner offormestions in Innervositions in Innervose。促进了范围的范围。这是跨越的范围。这些剪裁的模型。。 QWEN3版本还引起了全球AI和开放资源社区的关注,我们看到的也是一个充满赞誉的屏幕。它的表现如何?机器的心脏也做了一些简单的尝试。首先,有一个简单的推理测试问题,QWEN3-235B-A22B可以意外地处理它。 2倍快速动画接下来,我们尝试了一个更复杂的编程任务:用像素样式编写蛇游戏。同时还有另一个要求。在游戏中,有一个坦率的家伙追逐我们控制的蛇。咬伤时,蛇的长度一半将消失。当蛇撞到墙壁或咬伤时,游戏结束或长度不到2。该视频没有加速。 QWEN3-235B-A22B已在大约3个Minuto中使用了这项任务。经过简单的测试,我意识到它通常很有趣,但是有一些虫子,例如平顶家伙的速度非常快。但是考虑到这是QWEN3-235B-A2提供的镜头结果2b在简单的癫痫发作下,完全可以接受。我认为,更复杂的及时工程和次数优化可以取得更好的结果。我们还测试了Olllama的QWEN3系列QWEN 0.6B中最小的模型。看来,这种可以在普通手机上正确运行的小型模型不仅很快,而且足以完成许多阳光理性的活动。训练后的模型,例如QWEN3-30B-A3B及其预熟化的基座模型(例如基于QWEN3-30B-A3B)的模型现在可以在平面上购买,例如拥抱面,ModelsCope和Kaggle。对于部署,我们建议SGLANG和VLLM等框架;对于本地用途,强烈建议使用Olllama,Lmstudio,MLX,Llama.cpp和Ktransformers等工具。这些选项可确保用户可以轻松地将QWEN3在其工作流程中包括在内,无论是用于研究,开发还是劳动环境。目前,三个主要的亮点,QWEN3模型在许多方面都得到了增强。首先,两个支持思维方式,以下是:思维方式,模型逐渐推理,并在仔细考虑之后给出了最终答案,这适用于需要深思熟虑的复杂问题。模式不思考,模型为SimplyLeng问题提供了快速,近端的响应,该响应需要高于深度的速度。这种灵活性使用户可以根据特定的控制控制模型进行“思考”。例如,可以通过扩展理解措施来解决复杂的问题,而简单的问题可以直接快速地回答。至关重要的是,这两种模式的结合极大地提高了该模型实现稳定,有效控制“预算思维”的能力。 QWEN3提出的测量和平稳的性能改进与分配的计算信息推理预算直接相关。可以预测,这样的设计使用户更容易为多种玩家配置特定的预算。这下图显示了基准测试集中的无思想模式和心态的预算预算变化的趋势,例如AIME24,AIME25,LiveCodeBech(V5)和GPQA Diamond。其次,支持更多语言。当前,QWEN3模型支持119种语言和方言。改进的多语言功能为国际应用程序开辟了新的可能性,使更多的全球用户能够体验模型的强大技能。这些语言专门包括在以下内容中:第三,代理商的能力得到了增强。如今,该代理已成为大型模型领域的主要功能之一,尤其是最近引入了MCP模型上下文协议伟大的应用程序。目前,QWEN3模型和代码代码的功能得到了增强,包括加强对MCP的支持。我们可以查看以下示例(获取Qwenlm的库Markdown Content,然后绘制一个显示数字的条形图恒星的恒星),显示Qwen3如何与环境进行思考和相互作用:预训练数据达到36万亿代币和火车以获得混合的理解。就预训练而言,将QWEN3数据集与QWEN2.5进行了比较。 QWEN2.5在18万亿代币中进行了预训练,而Qwen3使用的数据量几乎是两倍,达到了近36万亿代币,涵盖了119种语言和方言。为了生成大型数据集,开发团队不仅从网络中收集数据,还从PDF文档中获取信息。他们使用QWEN2.5-VL从这些文档中获取文本,并提高了QWEN2.5所获得的内容的质量。此外,为了增加数学和代码数据的数量,开发团队在数学和代码字段中使用了两个专业模型,即QWEN2.5-MATH和QWEN2.5-编码,以合成数据,并合成不同的数据表格,包括教科书,问题和sidelines和Snippets。具体Y,预训练过程分为以下三个阶段:在第一阶段(S1),该模型先前接受了超过30万亿代币的训练,具有4K令牌上下文长度。这个阶段提供了基本语言技能和常识的模型。在第二阶段(S2)中,通过增加数据NA的比例(例如STEM,编程和推理活动)来改善数据集,然后在另外5万亿个代币中对模型进行培训。在最后阶段,使用高质量上下文数据将上下文的长度扩展到32K代币,以确保模型可以有效地处理更长的输入。由于改进了模型的体系结构,增加了培训数据和更有效的培训技术,因此QWEN3密度基本模型的整体性能与具有更多参数的QWEN2.5基本模型相当。例如,qwen3-1.7b/4b/8b/14b/32b基础与qwen2.5-3b/7b/7b/14b/32b/72b基础相当y。尤其是在STEM,编码和推理字段中,QWEN3密集的主模型的性能比较大的QWEN2.5模型更好。可以看出,QWEN3 MOE基本模型在QWEN2.5密集的基本模型中具有相似的性能,具有10%的激活参数,从而大量节省了培训和识别成本。同时,QWEN3在训练后阶段也进行了优化。为了提出一个混合模型,可以同时具有思考和推理并迅速做出反应的混合模型,开发团队已经实施了四个阶段的训练过程,包括:(1)长时间思考的连锁冷启动,(2)长时间思考的链条加强学习,(3)思维模式融合和(4)总体兴奋剂研究。在第一阶段,模型使用多种长期数据适当使用,涵盖了各种活动和领域,例如数学,代码,逻辑推理和STEM问题。此过程旨在为模型配备Pangi的基本功能Duction。二阶该段落的重点是在大规模加强研究中,使用基于规则的奖励来增强模型探索和研究技能。在第三阶段,该模型非常关注组合数据,包括长链思维数据和常用的教学数据正确调整,并结合了在思维模型中不思考的模式,确保推理和快速响应的不间断组合。在第四阶段,加强研究应用于20多个公共领域的活动,包括遵守教学,遵守格式以及代理商进一步增强模型的整体技能和适当不利行为的能力。 Qwen已成为世界开放资源的第一大型号。 Qwen3的发布是阿里巴巴·汤蒂·Qianwen的另一个里程碑。比较Llama 4系列模型收到的社区反馈,QWEN系列无疑成为了开放世界的数量NT也受到数据的支持。据了解,阿里巴巴·蒂吉(Alibaba Tgyyi)开设了200多个型号,在全球范围内下载了超过3亿个型号,源自QWEN的100,000多个型号,该模型超过了Llama,并成为世界上最大的开源组。随着时间的推移,QWEN,LLAMA和MISTRAL系列开放资源模型的衍生模型数量增加。在AI的全球技术激烈竞争的后面,阿里巴巴Thyi Qianwen通过持续的现代技术和开放合作促进了AI技术的知名度和发展,展示了TS技术公司在全球开放资源AI生态系统中的强大影响。参考链接:https://x.com/alibaba_qwen/status/19169620876766612998 我们珍惜您每一次在线询盘,有问必答,用专业的态度,贴心的服务。
让您真正感受到我们的与众不同!



 网站制作报价:0755-66889888 / 18898989988
网站制作报价:0755-66889888 / 18898989988







 888877777
888877777 18898989988
18898989988 0755-66889888
0755-66889888